17.1. Markov Decision Process (MDP)¶ Open the notebook in SageMaker Studio Lab
In this section, we will discuss how to formulate reinforcement learning problems using Markov decision processes (MDPs) and describe various components of MDPs in detail.
17.1.1. Definition of an MDP¶
A Markov decision process (MDP) (Bellman, 1957) is a model for how the state of a system evolves as different actions are applied to the system. A few different quantities come together to form an MDP.
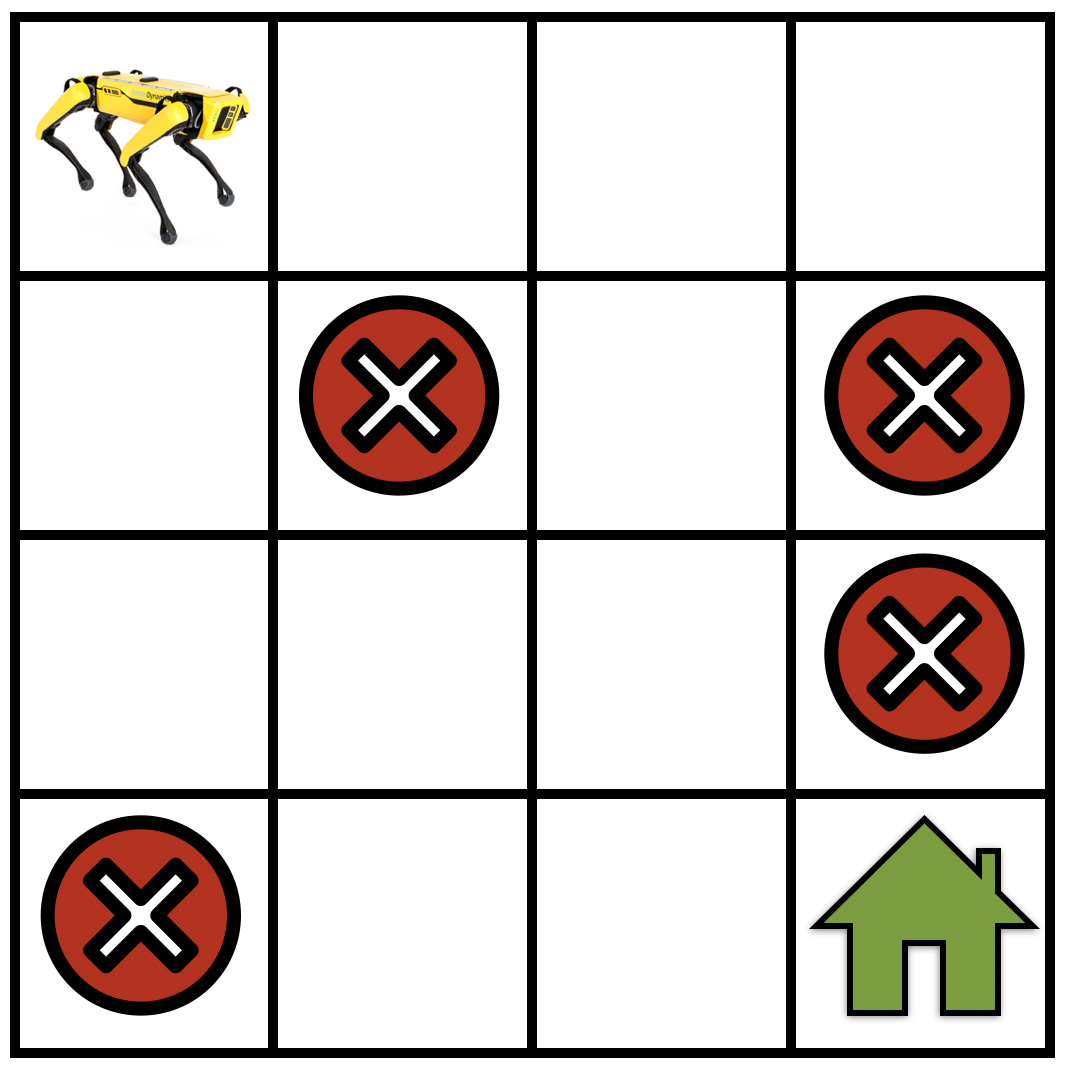
Fig. 17.1.1 A simple gridworld navigation task where the robot not only has to find its way to the goal location (shown as a green house) but also has to avoid trap locations (shown as red cross signs).¶
Let \(\mathcal{S}\) be the set of states in the MDP. As a concrete example see Fig. 17.1.1, for a robot that is navigating a gridworld. In this case, \(\mathcal{S}\) corresponds to the set of locations that the robot can be at any given timestep.
Let \(\mathcal{A}\) be the set of actions that the robot can take at each state, e.g., “go forward”, “turn right”, “turn left”, “stay at the same location”, etc. Actions can change the current state of the robot to some other state within the set \(\mathcal{S}\).
It may happen that we do not know how the robot moves exactly but only know it up to some approximation. We model this situation in reinforcement learning as follows: if the robot takes an action “go forward”, there might be a small probability that it stays at the current state, another small probability that it “turns left”, etc. Mathematically, this amounts to defining a “transition function” \(T: \mathcal{S} \times \mathcal{A} \times \mathcal{S} \to [0,1]\) such that \(T(s, a, s') = P(s' \mid s, a)\) using the conditional probability of reaching a state \(s'\) given that the robot was at state \(s\) and took an action \(a\). The transition function is a probability distribution and we therefore have \(\sum_{s' \in \mathcal{S}} T(s, a, s') = 1\) for all \(s \in \mathcal{S}\) and \(a \in \mathcal{A}\), i.e., the robot has to go to some state if it takes an action.
We now construct a notion of which actions are useful and which ones are not using the concept of a “reward” \(r: \mathcal{S} \times \mathcal{A} \to \mathbb{R}\). We say that the robot gets a reward \(r(s,a)\) if the robot takes an action \(a\) at state \(s\). If the reward \(r(s, a)\) is large, this indicates that taking the action \(a\) at state \(s\) is more useful to achieving the goal of the robot, i.e., going to the green house. If the reward \(r(s, a)\) is small, then action \(a\) is less useful to achieving this goal. It is important to note that the reward is designed by the user (the person who creates the reinforcement learning algorithm) with the goal in mind.
17.1.2. Return and Discount Factor¶
The different components above together form a Markov decision process (MDP)
Let’s now consider the situation when the robot starts at a particular state \(s_0 \in \mathcal{S}\) and continues taking actions to result in a trajectory
At each time step \(t\) the robot is at a state \(s_t\) and takes an action \(a_t\) which results in a reward \(r_t = r(s_t, a_t)\). The return of a trajectory is the total reward obtained by the robot along such a trajectory
The goal in reinforcement learning is to find a trajectory that has the largest return.
Think of the situation when the robot continues to travel in the gridworld without ever reaching the goal location. The sequence of states and actions in a trajectory can be infinitely long in this case and the return of any such infinitely long trajectory will be infinite. In order to keep the reinforcement learning formulation meaningful even for such trajectories, we introduce the notion of a discount factor \(\gamma < 1\). We write the discounted return as
Note that if \(\gamma\) is very small, the rewards earned by the robot in the far future, say \(t = 1000\), are heavily discounted by the factor \(\gamma^{1000}\). This encourages the robot to select short trajectories that achieve its goal, namely that of going to the green house in the gridwold example (see Fig. 17.1.1). For large values of the discount factor, say \(\gamma = 0.99\), the robot is encouraged to explore and then find the best trajectory to go to the goal location.
17.1.3. Discussion of the Markov Assumption¶
Let us think of a new robot where the state \(s_t\) is the location as above but the action \(a_t\) is the acceleration that the robot applies to its wheels instead of an abstract command like “go forward”. If this robot has some non-zero velocity at state \(s_t\), then the next location \(s_{t+1}\) is a function of the past location \(s_t\), the acceleration \(a_t\), also the velocity of the robot at time \(t\) which is proportional to \(s_t - s_{t-1}\). This indicates that we should have
the “some function” in our case would be Newton’s law of motion. This is quite different from our transition function that simply depends upon \(s_t\) and \(a_t\).
Markov systems are all systems where the next state \(s_{t+1}\) is only a function of the current state \(s_t\) and the action \(a_t\) taken at the current state. In Markov systems, the next state does not depend on which actions were taken in the past or the states that the robot was at in the past. For example, the new robot that has acceleration as the action above is not Markovian because the next location \(s_{t+1}\) depends upon the previous state \(s_{t-1}\) through the velocity. It may seem that Markovian nature of a system is a restrictive assumption, but it is not so. Markov Decision Processes are still capable of modeling a very large class of real systems. For example, for our new robot, if we chose our state \(s_t\) to the tuple \((\textrm{location}, \textrm{velocity})\) then the system is Markovian because its next state \((\textrm{location}_{t+1}, \textrm{velocity}_{t+1})\) depends only upon the current state \((\textrm{location}_t, \textrm{velocity}_t)\) and the action at the current state \(a_t\).
17.1.4. Summary¶
The reinforcement learning problem is typically modeled using Markov Decision Processes. A Markov decision process (MDP) is defined by a tuple of four entities \((\mathcal{S}, \mathcal{A}, T, r)\) where \(\mathcal{S}\) is the state space, \(\mathcal{A}\) is the action space, \(T\) is the transition function that encodes the transition probabilities of the MDP and \(r\) is the immediate reward obtained by taking action at a particular state.
17.1.5. Exercises¶
Suppose that we want to design an MDP to model MountainCar problem.
What would be the set of states?
What would be the set of actions?
What would be the possible reward functions?
How would you design an MDP for an Atari game like Pong game?