11.2. Attention Pooling by Similarity¶ Open the notebook in SageMaker Studio Lab
Now that we have introduced the primary components of the attention mechanism, let’s use them in a rather classical setting, namely regression and classification via kernel density estimation (Nadaraya, 1964, Watson, 1964). This detour simply provides additional background: it is entirely optional and can be skipped if needed. At their core, Nadaraya–Watson estimators rely on some similarity kernel \(\alpha(\mathbf{q}, \mathbf{k})\) relating queries \(\mathbf{q}\) to keys \(\mathbf{k}\). Some common kernels are
There are many more choices that we could pick. See a Wikipedia article for a more extensive review and how the choice of kernels is related to kernel density estimation, sometimes also called Parzen Windows (Parzen, 1957). All of the kernels are heuristic and can be tuned. For instance, we can adjust the width, not only on a global basis but even on a per-coordinate basis. Regardless, all of them lead to the following equation for regression and classification alike:
In the case of a (scalar) regression with observations \((\mathbf{x}_i, y_i)\) for features and labels respectively, \(\mathbf{v}_i = y_i\) are scalars, \(\mathbf{k}_i = \mathbf{x}_i\) are vectors, and the query \(\mathbf{q}\) denotes the new location where \(f\) should be evaluated. In the case of (multiclass) classification, we use one-hot-encoding of \(y_i\) to obtain \(\mathbf{v}_i\). One of the convenient properties of this estimator is that it requires no training. Even more so, if we suitably narrow the kernel with increasing amounts of data, the approach is consistent (Mack and Silverman, 1982), i.e., it will converge to some statistically optimal solution. Let’s start by inspecting some kernels.
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
d2l.use_svg_display()
from mxnet import autograd, gluon, np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2l
npx.set_np()
d2l.use_svg_display()
import jax
from flax import linen as nn
from jax import numpy as jnp
from d2l import jax as d2l
No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
import numpy as np
import tensorflow as tf
from d2l import tensorflow as d2l
d2l.use_svg_display()
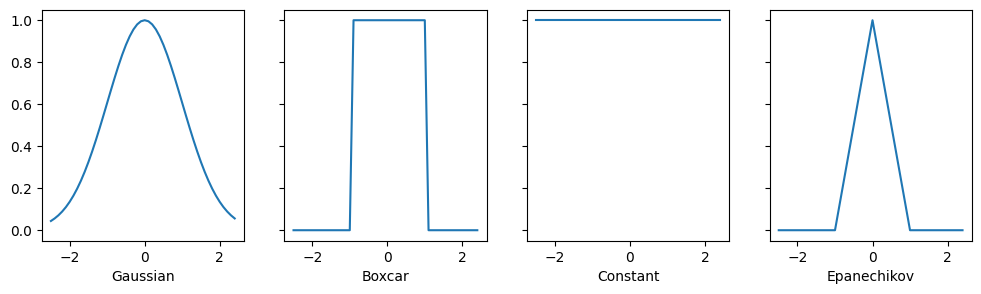
11.2.1. Kernels and Data¶
All the kernels \(\alpha(\mathbf{k}, \mathbf{q})\) defined in this section are translation and rotation invariant; that is, if we shift and rotate \(\mathbf{k}\) and \(\mathbf{q}\) in the same manner, the value of \(\alpha\) remains unchanged. For simplicity we thus pick scalar arguments \(k, q \in \mathbb{R}\) and pick the key \(k = 0\) as the origin. This yields:
# Define some kernels
def gaussian(x):
return torch.exp(-x**2 / 2)
def boxcar(x):
return torch.abs(x) < 1.0
def constant(x):
return 1.0 + 0 * x
def epanechikov(x):
return torch.max(1 - torch.abs(x), torch.zeros_like(x))
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
kernels = (gaussian, boxcar, constant, epanechikov)
names = ('Gaussian', 'Boxcar', 'Constant', 'Epanechikov')
x = torch.arange(-2.5, 2.5, 0.1)
for kernel, name, ax in zip(kernels, names, axes):
ax.plot(x.detach().numpy(), kernel(x).detach().numpy())
ax.set_xlabel(name)
d2l.plt.show()

# Define some kernels
def gaussian(x):
return np.exp(-x**2 / 2)
def boxcar(x):
return np.abs(x) < 1.0
def constant(x):
return 1.0 + 0 * x
def epanechikov(x):
return np.maximum(1 - np.abs(x), 0)
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
kernels = (gaussian, boxcar, constant, epanechikov)
names = ('Gaussian', 'Boxcar', 'Constant', 'Epanechikov')
x = np.arange(-2.5, 2.5, 0.1)
for kernel, name, ax in zip(kernels, names, axes):
ax.plot(x.asnumpy(), kernel(x).asnumpy())
ax.set_xlabel(name)
d2l.plt.show()
[22:04:09] ../src/storage/storage.cc:196: Using Pooled (Naive) StorageManager for CPU

# Define some kernels
def gaussian(x):
return jnp.exp(-x**2 / 2)
def boxcar(x):
return jnp.abs(x) < 1.0
def constant(x):
return 1.0 + 0 * x
def epanechikov(x):
return jnp.maximum(1 - jnp.abs(x), 0)
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
kernels = (gaussian, boxcar, constant, epanechikov)
names = ('Gaussian', 'Boxcar', 'Constant', 'Epanechikov')
x = jnp.arange(-2.5, 2.5, 0.1)
for kernel, name, ax in zip(kernels, names, axes):
ax.plot(x, kernel(x))
ax.set_xlabel(name)
d2l.plt.show()
# Define some kernels
def gaussian(x):
return tf.exp(-x**2 / 2)
def boxcar(x):
return tf.abs(x) < 1.0
def constant(x):
return 1.0 + 0 * x
def epanechikov(x):
return tf.maximum(1 - tf.abs(x), 0)
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
kernels = (gaussian, boxcar, constant, epanechikov)
names = ('Gaussian', 'Boxcar', 'Constant', 'Epanechikov')
x = tf.range(-2.5, 2.5, 0.1)
for kernel, name, ax in zip(kernels, names, axes):
ax.plot(x.numpy(), kernel(x).numpy())
ax.set_xlabel(name)
d2l.plt.show()

Different kernels correspond to different notions of range and smoothness. For instance, the boxcar kernel only attends to observations within a distance of \(1\) (or some otherwise defined hyperparameter) and does so indiscriminately.
To see Nadaraya–Watson estimation in action, let’s define some training data. In the following we use the dependency
where \(\epsilon\) is drawn from a normal distribution with zero mean and unit variance. We draw 40 training examples.
def f(x):
return 2 * torch.sin(x) + x
n = 40
x_train, _ = torch.sort(torch.rand(n) * 5)
y_train = f(x_train) + torch.randn(n)
x_val = torch.arange(0, 5, 0.1)
y_val = f(x_val)
def f(x):
return 2 * np.sin(x) + x
n = 40
x_train = np.sort(np.random.rand(n) * 5, axis=None)
y_train = f(x_train) + np.random.randn(n)
x_val = np.arange(0, 5, 0.1)
y_val = f(x_val)
def f(x):
return 2 * jnp.sin(x) + x
n = 40
x_train = jnp.sort(jax.random.uniform(d2l.get_key(), (n,)) * 5)
y_train = f(x_train) + jax.random.normal(d2l.get_key(), (n,))
x_val = jnp.arange(0, 5, 0.1)
y_val = f(x_val)
def f(x):
return 2 * tf.sin(x) + x
n = 40
x_train = tf.sort(tf.random.uniform((n,1)) * 5, 0)
y_train = f(x_train) + tf.random.normal((n, 1))
x_val = tf.range(0, 5, 0.1)
y_val = f(x_val)
11.2.2. Attention Pooling via Nadaraya–Watson Regression¶
Now that we have data and kernels, all we need is a function that
computes the kernel regression estimates. Note that we also want to
obtain the relative kernel weights in order to perform some minor
diagnostics. Hence we first compute the kernel between all training
features (covariates) x_train and all validation features x_val.
This yields a matrix, which we subsequently normalize. When multiplied
with the training labels y_train we obtain the estimates.
Recall attention pooling in (11.1.1). Let each
validation feature be a query, and each training feature–label pair be a
key–value pair. As a result, the normalized relative kernel weights
(attention_w below) are the attention weights.
def nadaraya_watson(x_train, y_train, x_val, kernel):
dists = x_train.reshape((-1, 1)) - x_val.reshape((1, -1))
# Each column/row corresponds to each query/key
k = kernel(dists).type(torch.float32)
# Normalization over keys for each query
attention_w = k / k.sum(0)
y_hat = y_train@attention_w
return y_hat, attention_w
def nadaraya_watson(x_train, y_train, x_val, kernel):
dists = x_train.reshape((-1, 1)) - x_val.reshape((1, -1))
# Each column/row corresponds to each query/key
k = kernel(dists).astype(np.float32)
# Normalization over keys for each query
attention_w = k / k.sum(0)
y_hat = np.dot(y_train, attention_w)
return y_hat, attention_w
def nadaraya_watson(x_train, y_train, x_val, kernel):
dists = x_train.reshape((-1, 1)) - x_val.reshape((1, -1))
# Each column/row corresponds to each query/key
k = kernel(dists).astype(jnp.float32)
# Normalization over keys for each query
attention_w = k / k.sum(0)
y_hat = y_train@attention_w
return y_hat, attention_w
def nadaraya_watson(x_train, y_train, x_val, kernel):
dists = tf.reshape(x_train, (-1, 1)) - tf.reshape(x_val, (1, -1))
# Each column/row corresponds to each query/key
k = tf.cast(kernel(dists), tf.float32)
# Normalization over keys for each query
attention_w = k / tf.reduce_sum(k, 0)
y_hat = tf.transpose(tf.transpose(y_train)@attention_w)
return y_hat, attention_w
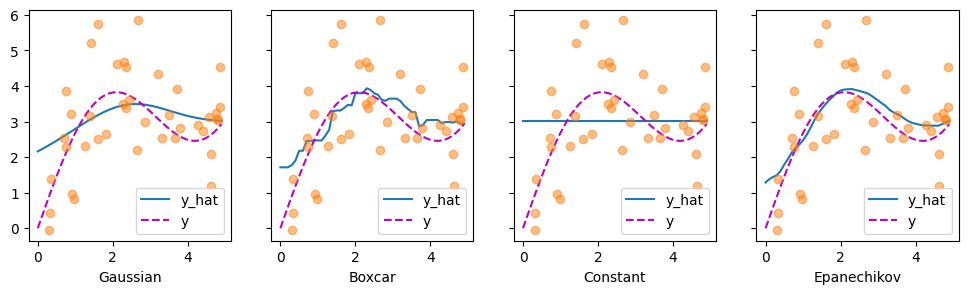
Let’s have a look at the kind of estimates that the different kernels produce.
def plot(x_train, y_train, x_val, y_val, kernels, names, attention=False):
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
for kernel, name, ax in zip(kernels, names, axes):
y_hat, attention_w = nadaraya_watson(x_train, y_train, x_val, kernel)
if attention:
pcm = ax.imshow(attention_w.detach().numpy(), cmap='Reds')
else:
ax.plot(x_val, y_hat)
ax.plot(x_val, y_val, 'm--')
ax.plot(x_train, y_train, 'o', alpha=0.5);
ax.set_xlabel(name)
if not attention:
ax.legend(['y_hat', 'y'])
if attention:
fig.colorbar(pcm, ax=axes, shrink=0.7)
plot(x_train, y_train, x_val, y_val, kernels, names)

def plot(x_train, y_train, x_val, y_val, kernels, names, attention=False):
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
for kernel, name, ax in zip(kernels, names, axes):
y_hat, attention_w = nadaraya_watson(x_train, y_train, x_val, kernel)
if attention:
pcm = ax.imshow(attention_w.asnumpy(), cmap='Reds')
else:
ax.plot(x_val, y_hat)
ax.plot(x_val, y_val, 'm--')
ax.plot(x_train, y_train, 'o', alpha=0.5);
ax.set_xlabel(name)
if not attention:
ax.legend(['y_hat', 'y'])
if attention:
fig.colorbar(pcm, ax=axes, shrink=0.7)
plot(x_train, y_train, x_val, y_val, kernels, names)

def plot(x_train, y_train, x_val, y_val, kernels, names, attention=False):
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
for kernel, name, ax in zip(kernels, names, axes):
y_hat, attention_w = nadaraya_watson(x_train, y_train, x_val, kernel)
if attention:
pcm = ax.imshow(attention_w, cmap='Reds')
else:
ax.plot(x_val, y_hat)
ax.plot(x_val, y_val, 'm--')
ax.plot(x_train, y_train, 'o', alpha=0.5);
ax.set_xlabel(name)
if not attention:
ax.legend(['y_hat', 'y'])
if attention:
fig.colorbar(pcm, ax=axes, shrink=0.7)
plot(x_train, y_train, x_val, y_val, kernels, names)
def plot(x_train, y_train, x_val, y_val, kernels, names, attention=False):
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
for kernel, name, ax in zip(kernels, names, axes):
y_hat, attention_w = nadaraya_watson(x_train, y_train, x_val, kernel)
if attention:
pcm = ax.imshow(attention_w.numpy(), cmap='Reds')
else:
ax.plot(x_val, y_hat)
ax.plot(x_val, y_val, 'm--')
ax.plot(x_train, y_train, 'o', alpha=0.5);
ax.set_xlabel(name)
if not attention:
ax.legend(['y_hat', 'y'])
if attention:
fig.colorbar(pcm, ax=axes, shrink=0.7)
plot(x_train, y_train, x_val, y_val, kernels, names)

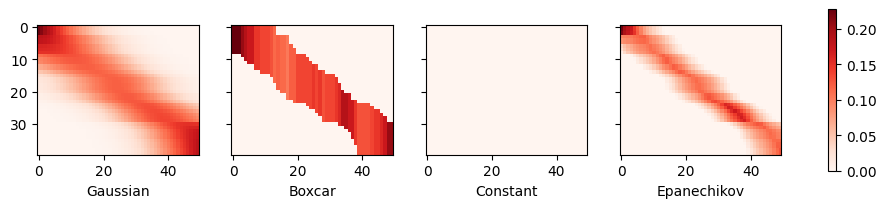
The first thing that stands out is that all three nontrivial kernels (Gaussian, Boxcar, and Epanechikov) produce fairly workable estimates that are not too far from the true function. Only the constant kernel that leads to the trivial estimate \(f(x) = \frac{1}{n} \sum_i y_i\) produces a rather unrealistic result. Let’s inspect the attention weighting a bit more closely:
plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)

plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)

plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)
plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)

The visualization clearly shows why the estimates for Gaussian, Boxcar, and Epanechikov are very similar: after all, they are derived from very similar attention weights, despite the different functional form of the kernel. This raises the question as to whether this is always the case.
11.2.3. Adapting Attention Pooling¶
We could replace the Gaussian kernel with one of a different width. That is, we could use \(\alpha(\mathbf{q}, \mathbf{k}) = \exp\left(-\frac{1}{2 \sigma^2} \|\mathbf{q} - \mathbf{k}\|^2 \right)\) where \(\sigma^2\) determines the width of the kernel. Let’s see whether this affects the outcomes.
sigmas = (0.1, 0.2, 0.5, 1)
names = ['Sigma ' + str(sigma) for sigma in sigmas]
def gaussian_with_width(sigma):
return (lambda x: torch.exp(-x**2 / (2*sigma**2)))
kernels = [gaussian_with_width(sigma) for sigma in sigmas]
plot(x_train, y_train, x_val, y_val, kernels, names)

sigmas = (0.1, 0.2, 0.5, 1)
names = ['Sigma ' + str(sigma) for sigma in sigmas]
def gaussian_with_width(sigma):
return (lambda x: np.exp(-x**2 / (2*sigma**2)))
kernels = [gaussian_with_width(sigma) for sigma in sigmas]
plot(x_train, y_train, x_val, y_val, kernels, names)

sigmas = (0.1, 0.2, 0.5, 1)
names = ['Sigma ' + str(sigma) for sigma in sigmas]
def gaussian_with_width(sigma):
return (lambda x: jnp.exp(-x**2 / (2*sigma**2)))
kernels = [gaussian_with_width(sigma) for sigma in sigmas]
plot(x_train, y_train, x_val, y_val, kernels, names)
sigmas = (0.1, 0.2, 0.5, 1)
names = ['Sigma ' + str(sigma) for sigma in sigmas]
def gaussian_with_width(sigma):
return (lambda x: tf.exp(-x**2 / (2*sigma**2)))
kernels = [gaussian_with_width(sigma) for sigma in sigmas]
plot(x_train, y_train, x_val, y_val, kernels, names)

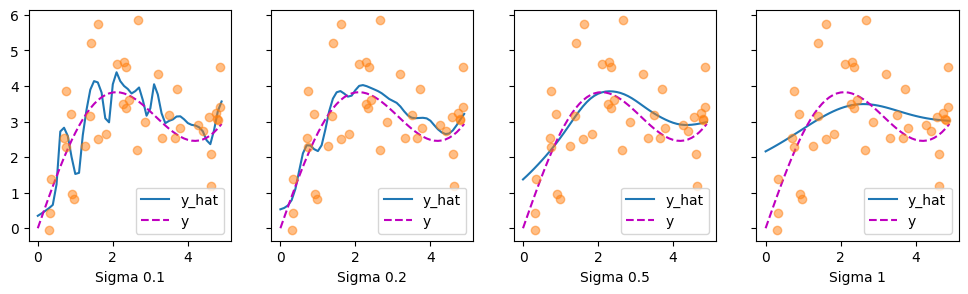
Clearly, the narrower the kernel, the less smooth the estimate. At the same time, it adapts better to the local variations. Let’s look at the corresponding attention weights.
plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)

plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)

plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)
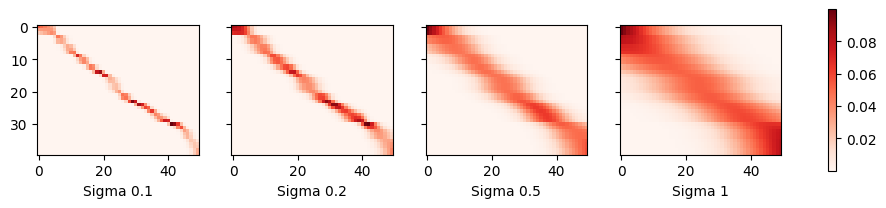
plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)

As we would expect, the narrower the kernel, the narrower the range of large attention weights. It is also clear that picking the same width might not be ideal. In fact, Silverman (1986) proposed a heuristic that depends on the local density. Many more such “tricks” have been proposed. For instance, Norelli et al. (2022) used a similar nearest-neighbor interpolation technique for designing cross-modal image and text representations.
The astute reader might wonder why we are providing this deep dive for a method that is over half a century old. First, it is one of the earliest precursors of modern attention mechanisms. Second, it is great for visualization. Third, and just as importantly, it demonstrates the limits of hand-crafted attention mechanisms. A much better strategy is to learn the mechanism, by learning the representations for queries and keys. This is what we will embark on in the following sections.
11.2.4. Summary¶
Nadaraya–Watson kernel regression is an early precursor of the current attention mechanisms. It can be used directly with little to no training or tuning, either for classification or regression. The attention weight is assigned according to the similarity (or distance) between query and key, and according to how many similar observations are available.
11.2.5. Exercises¶
Parzen windows density estimates are given by \(\hat{p}(\mathbf{x}) = \frac{1}{n} \sum_i k(\mathbf{x}, \mathbf{x}_i)\). Prove that for binary classification the function \(\hat{p}(\mathbf{x}, y=1) - \hat{p}(\mathbf{x}, y=-1)\), as obtained by Parzen windows is equivalent to Nadaraya–Watson classification.
Implement stochastic gradient descent to learn a good value for kernel widths in Nadaraya–Watson regression.
What happens if you just use the above estimates to minimize \((f(\mathbf{x_i}) - y_i)^2\) directly? Hint: \(y_i\) is part of the terms used to compute \(f\).
Remove \((\mathbf{x}_i, y_i)\) from the estimate for \(f(\mathbf{x}_i)\) and optimize over the kernel widths. Do you still observe overfitting?
Assume that all \(\mathbf{x}\) lie on the unit sphere, i.e., all satisfy \(\|\mathbf{x}\| = 1\). Can you simplify the \(\|\mathbf{x} - \mathbf{x}_i\|^2\) term in the exponential? Hint: we will later see that this is very closely related to dot product attention.
Recall that Mack and Silverman (1982) proved that Nadaraya–Watson estimation is consistent. How quickly should you reduce the scale for the attention mechanism as you get more data? Provide some intuition for your answer. Does it depend on the dimensionality of the data? How?